Laravel importando CSV com grande volume de dados
Importação Eficiente: Processamento Otimizado e Controle de Memória
Neste projeto, desenvolvi uma solução eficiente para importar grandes volumes de dados de arquivos CSV para o banco de dados, enfrentando desafios típicos como a variação de formatos de data, o alto consumo de memória e a necessidade de processamento em tempo real. Para garantir a consistência dos dados, criei funções personalizadas para padronizar as datas, além de implementar um controle de fluxo que evita o estouro de memória, processando os arquivos em blocos de mil linhas. Essas estratégias asseguram que o sistema mantenha alta performance e seja capaz de lidar com grandes volumes de dados sem comprometer a estabilidade.
Além disso, para melhorar a experiência do usuário, integrei uma abordagem assíncrona utilizando filas do Laravel, permitindo que o processamento ocorra em segundo plano. O usuário pode acompanhar o status da importação em tempo real por meio de um relatório atualizado constantemente. Com essas soluções, o sistema é capaz de realizar importações grandes de forma segura, eficiente e sem impactar a utilização do sistema por parte do usuário, garantindo um processo fluido e transparente.
Categoria
Ferramentas utilizadas
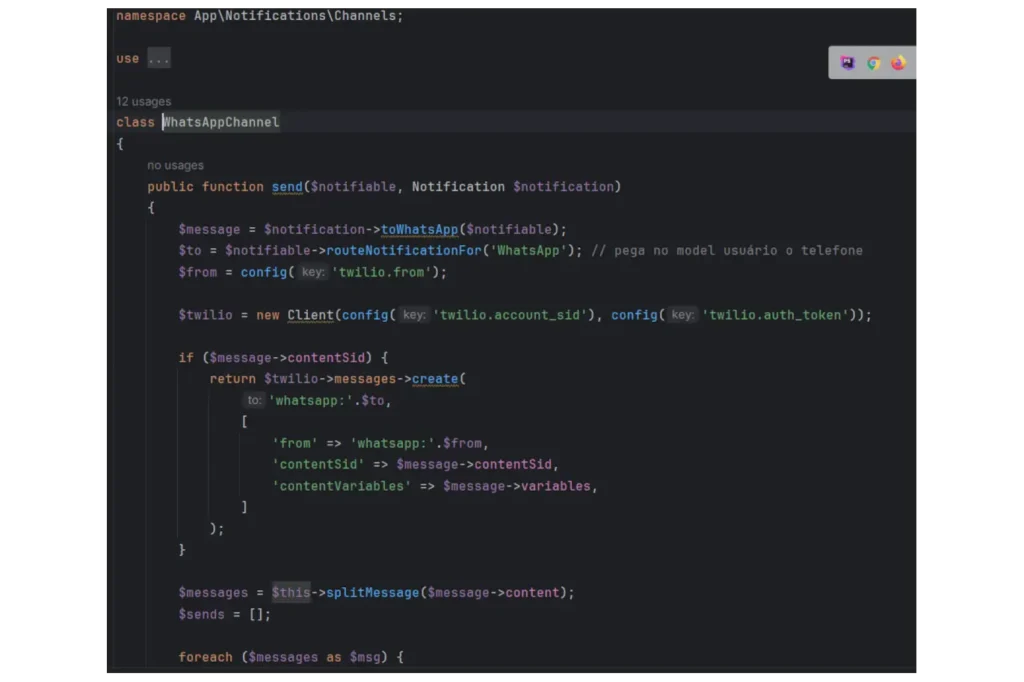
Autenticação de Usuário
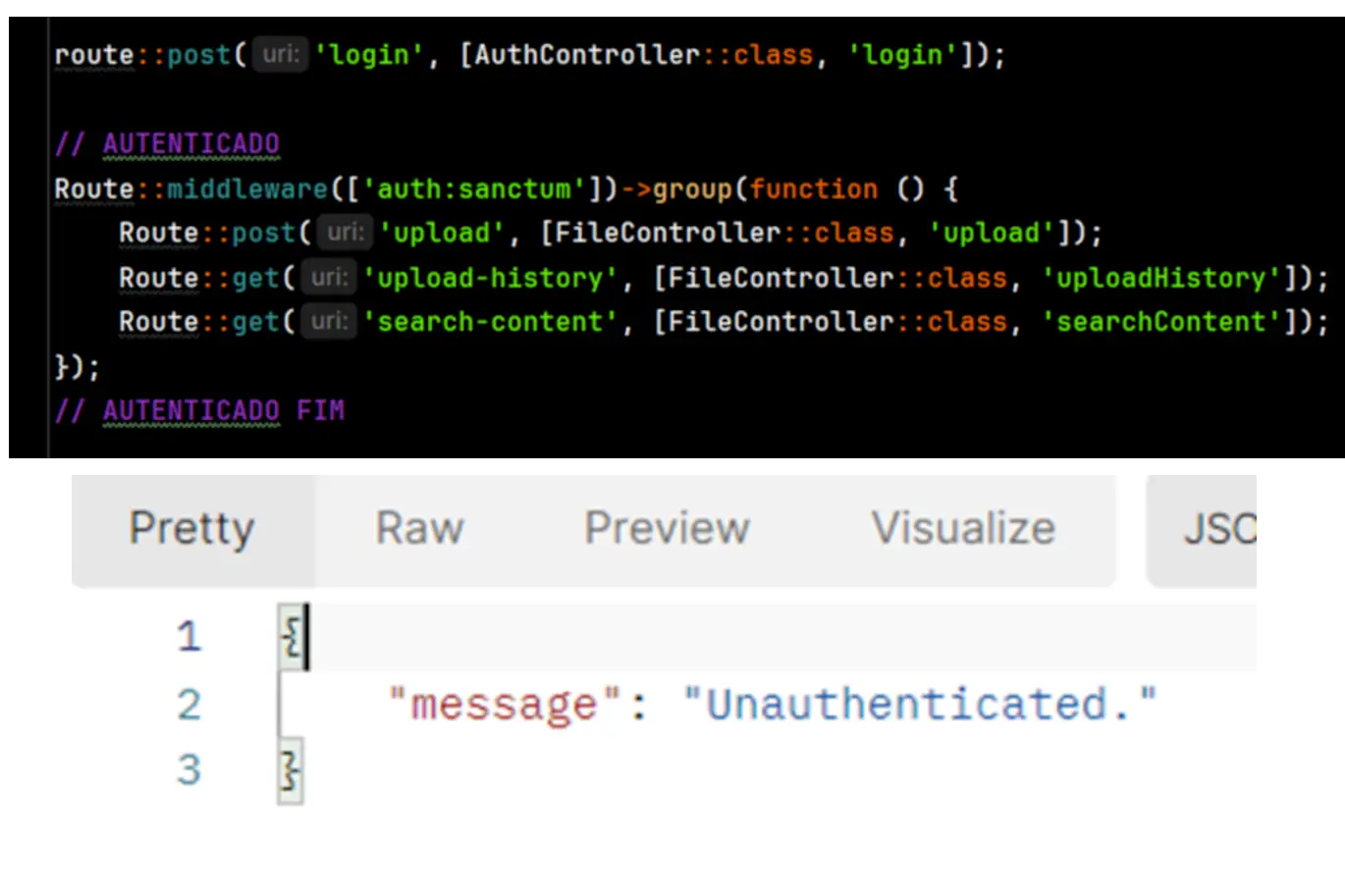
Para atender a essa necessidade, utilizei o Laravel Sanctum, uma ferramenta poderosa para autenticação de usuários. Com ela, garantimos que cada solicitação fosse feita de forma segura, permitindo que apenas usuários logados pudessem acessar e realizar a importação dos arquivos CSV.
Como Funciona?
- Autenticação de Usuário: O Sanctum foi implementado para autenticar os usuários antes de permitir qualquer operação de importação, assegurando que somente usuários com permissões adequadas pudessem realizar o processo.
Envio de Arquivos Único com Validação de Nome
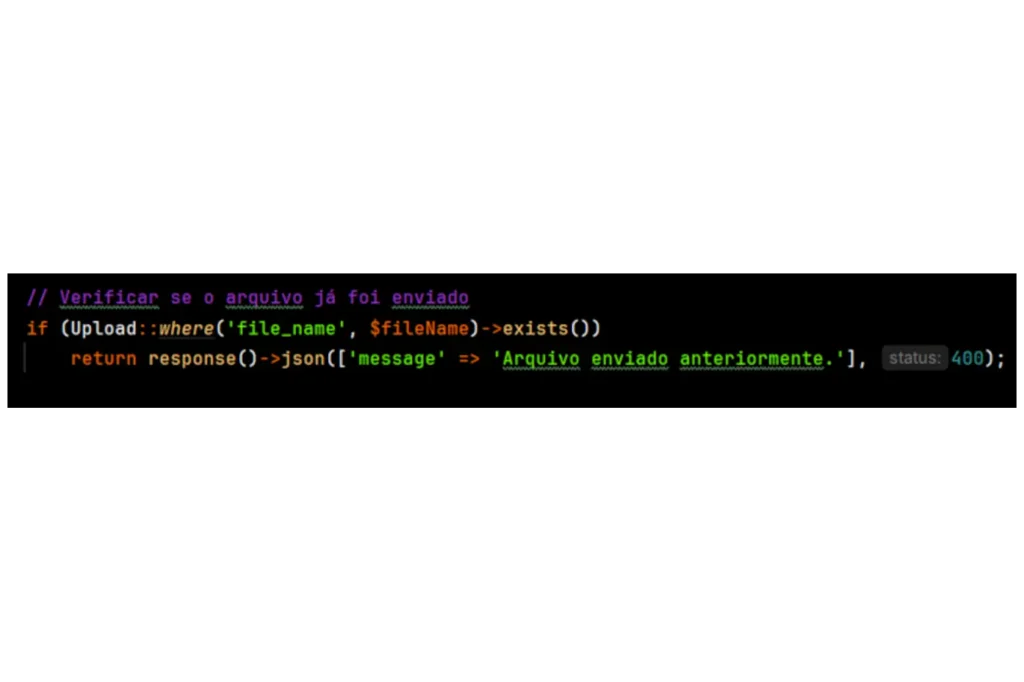
Outro requisito importante deste sistema foi garantir que cada arquivo CSV pudesse ser enviado apenas uma vez. Para isso, implementei uma verificação que assegura que um arquivo com o mesmo nome não possa ser importado mais de uma vez, evitando duplicação de dados e mantendo a integridade do sistema.
Como Funciona?
- Verificação de Arquivo: Ao realizar o upload, o sistema verifica se um arquivo com o mesmo nome já foi enviado anteriormente. Caso positivo, a importação é bloqueada, evitando que o arquivo seja carregado novamente.
- Exceção para Alteração de Nome: Se o arquivo tiver o nome modificado, o sistema considera o arquivo como novo, permitindo o envio novamente. Isso garante flexibilidade para os usuários sem comprometer a segurança e a organização dos dados.
- Prevenção de Duplicação de Dados: Essa validação assegura que não haja registros duplicados no banco de dados, mantendo a qualidade e precisão das informações importadas.
Esse processo simples e eficaz de verificação de arquivos permite um controle mais rigoroso sobre os dados importados, garantindo uma experiência segura e sem erros para os usuários.
Processamento em Segundo Plano com Filas e Relatório de Status
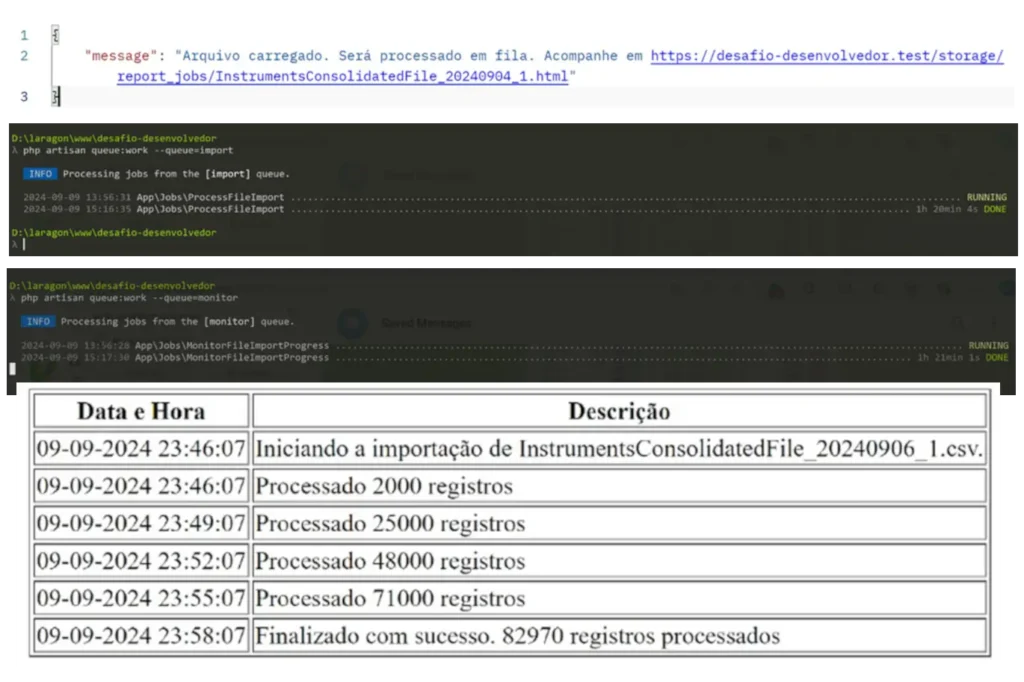
Considerando o grande volume de dados a ser importado, implementei uma solução utilizando filas no Laravel para garantir que o processo de importação não bloqueasse o uso do sistema pelo usuário. O arquivo CSV é processado em segundo plano, enquanto um relatório de status é atualizado em tempo real para que o usuário acompanhe o progresso da importação sem interrupções.
Como Funciona?
- Processamento em Segundo Plano: Utilizando duas filas no Laravel, o arquivo enviado é processado de forma assíncrona. A primeira fila trata da importação dos dados, enquanto a segunda é responsável pela atualização de um relatório de status em HTML.
- Relatório de Status: Durante o processamento, o usuário recebe um link para acessar o relatório gerado, onde pode acompanhar o progresso da importação, como o número de registros processados, erros (se houver) e outras informações relevantes.
Essa abordagem permite que o sistema lide com grandes volumes de dados de maneira eficiente e sem sobrecarregar o usuário, proporcionando uma experiência tranquila e transparente durante todo o processo de importação.
Padronização de Data para Importação Consistente
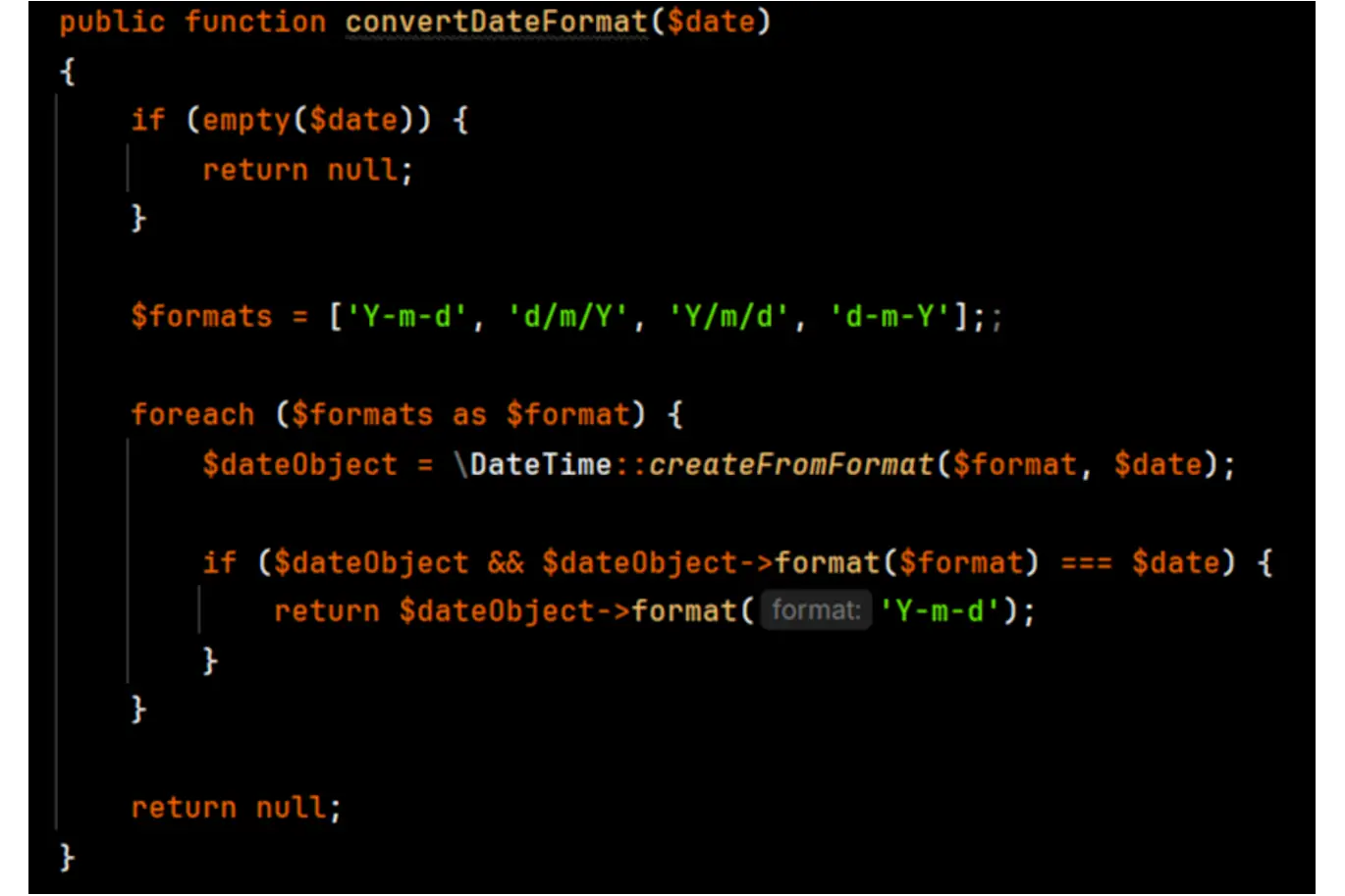
Uma das tarefas essenciais deste projeto foi garantir que as datas importadas dos arquivos CSV seguissem um formato consistente, independentemente do padrão utilizado no arquivo original. Como as datas nos arquivos CSV podiam vir em diferentes formatos, desenvolvi uma função personalizada para padronizar automaticamente as datas antes de inseri-las no banco de dados.
Como Funciona?
- Detecção e Conversão de Formatos: A função identifica os diferentes formatos de data presentes no arquivo CSV e converte todos para um formato único e padronizado, como “YYYY-MM-DD”. Isso garante que as datas sejam uniformes, facilitando o processamento e a análise posterior.
- Prevenção de Erros: Ao padronizar as datas durante o processo de importação, a função elimina possíveis erros de formatação que poderiam comprometer a qualidade dos dados no banco.
- Flexibilidade para Diversos Formatos: A função foi projetada para ser flexível e lidar com uma variedade de formatos de data comuns em arquivos CSV, assegurando que a importação seja sempre bem-sucedida, independentemente das diferenças de formatação.
Essa abordagem não só melhora a qualidade dos dados importados, mas também otimiza a integração de diferentes fontes de informações, garantindo que as datas estejam sempre corretas e no formato ideal para análise e uso.
Gestão de Memória Otimizada: Processamento em Blocos de Mil Linhas
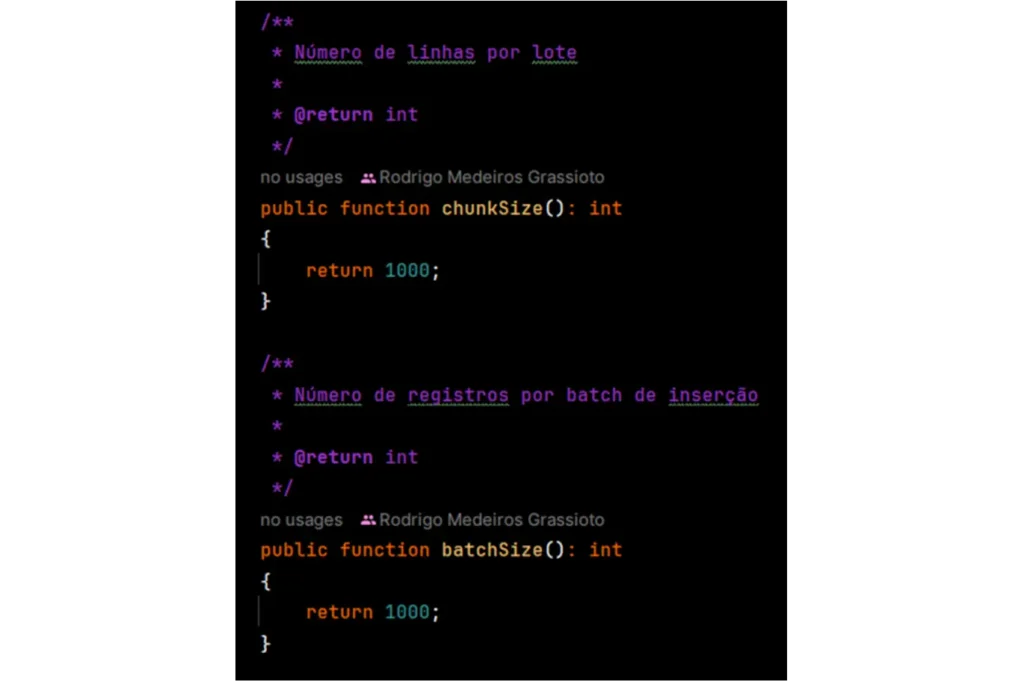
Para contornar o problema de estouro de memória durante o processamento de grandes volumes de dados, implementei uma estratégia de processamento em blocos. O arquivo CSV é lido e processado em segmentos de mil linhas por vez, evitando que o sistema sobrecarregue a memória e garantindo um desempenho estável durante toda a importação.
Como Funciona?
- Processamento em Blocos: Ao invés de carregar o arquivo inteiro na memória de uma vez, o sistema lê e processa apenas mil linhas por vez, permitindo que a memória seja utilizada de forma eficiente.
- Liberação de Memória: Após o processamento de cada bloco de mil linhas, a memória é liberada antes de iniciar a próxima iteração, prevenindo o estouro de memória e mantendo o desempenho do sistema em níveis ideais.
- Eficiência no Processamento: Essa abordagem permite que arquivos CSV com um grande número de linhas sejam processados de forma rápida e sem falhas, garantindo que mesmo arquivos volumosos sejam importados sem comprometer o funcionamento do sistema.
Com essa solução, foi possível garantir a integridade do sistema durante o processamento de grandes volumes de dados, mantendo a performance e evitando interrupções por falta de memória.
Código Limpo e Escalável para Projetos Sustentáveis
Adotamos a prática de código limpo e bem estruturado, facilitando a leitura, compreensão e manutenção do sistema. Isso não só garante eficiência, mas também possibilita a escalabilidade do seu projeto conforme suas necessidades crescem.
Benefícios do Código Limpo:
- Facilidade de Manutenção: Com um código bem escrito, as futuras alterações e atualizações podem ser feitas com rapidez e sem complicações.
- Leitura e Compreensão Simplificadas: A clareza do código torna mais fácil para outros desenvolvedores entenderem e trabalharem no projeto, promovendo uma colaboração eficaz.
- Escalabilidade Garantida: Estruturas bem organizadas permitem que o projeto cresça sem comprometer sua performance, proporcionando uma evolução contínua e sem problemas.
Este projeto demonstrou como é possível lidar com grandes volumes de dados de maneira eficiente e segura, utilizando as poderosas ferramentas do Laravel. Com soluções como o processamento em blocos para evitar estouro de memória, a padronização automática das datas e a utilização de filas para processos assíncronos, conseguimos criar um sistema robusto, rápido e escalável. A combinação dessas técnicas garantiu não apenas a integridade e a performance do sistema, mas também uma experiência tranquila para os usuários, que podem acompanhar o status do processamento em tempo real. O resultado é uma solução inteligente e confiável para importar dados em grande escala sem comprometer a eficiência ou a qualidade.
Outros Trabalhos
Explore outros projetos desenvolvidos com a mesma tecnologia e inovação, que demonstram como podemos transformar desafios em soluções eficientes e escaláveis. Clique abaixo para ver mais exemplos de como nossos sistemas inteligentes podem otimizar diferentes processos e atender às suas necessidades.
UI / UX Design
Ruma Web Design
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
UI / UX Design
Campusa Web Design
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.

UI / UX Design
Lapar Web Design
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.